
Streamr 1.0 Mainnet is LIVE! Decentralized Data Broadcasting has Arrived!
The Streamr Network 1.0 mainnet, a landmark milestone that signifies the completion of the original 2017 roadmap, is live! Read more

Preparing your Operator for Streamr 1.0 mainnet
The Streamr 1.0 mainnet launch is getting closer, and now is the time for Operators to prepare by taking a few steps. Read more

When AI connects with Streamr: The era of real-time generative intelligence
What happens when artificial intelligence (AI) joins forces with Streamr– the unstoppable real-time data network? In this post, we’ll walk through the fundamentals of how the next generation… Read more

Create your Operator and get Prepared for Streamr 1.0 Incentivised Testnets!
Testnet 1, the first Streamr 1.0 incentivised testnet, goes live in 1 week! It’s time to get prepared for the 5 million DATA tokens. Read more

AI Meets Decentralized Data: get to know Streamr’s Winners of the LearnWeb3 Hackathon
This meeting of artificial intelligence and decentralized real-time data holds a lot of potential for experimentation, as both become more ubiquitous. That’s why we were delighted to offer… Read more
Breaking new ground with decentralized incentivizes in Streamr 1.0
The final milestone of the Streamr project arrives later this year and with it comes the long awaited incentive layer that activates the DATA token economy. Those familiar… Read more

KYVE Integrates with Streamr to Add Streams of Validated Data to The Hub
Building on our collaboration in the development of Log Store, we’re delighted to announce that KYVE, a Web3 solution for both on-chain and off-chain decentralized data validation, has… Read more

Streamr Open Data Challenge: Round two Winners!
Let’s take a look at the winners of round two of the Streamr Open Data Challenge. After a successful debut, we moved the contest to the LearnWeb3 platform to… Read more

Streamr and MapMetrics Team Up to Champion Open Mobility Data in Web3 and Reward Node Runners
We’re pleased to announce a collaboration with MapMetrics for a series of open data initiatives and node contest engagements. MapMetrics is a drive-to-earn navigation app that rewards its users in… Read more
Streamr Open Data Challenge: Moving to LearnWeb3 and Celebrating Round One Winners!
We are thrilled to announce that the Streamr Open Data Challenge, a contest to add new real-time data streams to The Hub, has transitioned to LearnWeb3! We believe this move… Read more

Streaming file transfer over Streamr Network
Everyone knows what file transfers are but transferring files over a pub/sub system is an atypical use case for a distributed messaging system. At Streamr we have been… Read more

Log Store Network launches AlphaNet: leveraging KYVE and Arweave to turn the Streamr Network into an Immutable & Tamper-proof Time-series Database.
Log Store was proposed to Streamr Governance to enable automatic decentralised permanent storage of any data transmitted over the Streamr Network. The problem that sparked this project is… Read more
See more Streamr News
Guides & tutorials
Learn to build with Streamr and read our guides to Web3 technology, tools and use cases.

What is DePIN? Learn How Crypto is Powering Physical Networks of the Future
Whenever us nerds get excited about a new technology – like personal computers, the internet or smartphones – the public dutifully yells, “WHERE ARE THE USE CASES”? And… Read more

A Guide to Web3 Developer Tools (Ethereum)
It has never been a better time to be a Web3 developer. There has been a large amount of growth in developer tools. These tools aim to make… Read more

How to build a Streamr Node Dashboard with Streamlit and Python
Let’s say this is the first time you’ve heard or read about Streamr Network and Streamlit; if you are already aware, then bear with me as I give… Read more

Developer DAO: Become a better Web3 developer and find your crowd
When someone enters the Web3 space, the first thing they do is look for educational content. After all, they want to learn what this new decentralized paradigm is… Read more
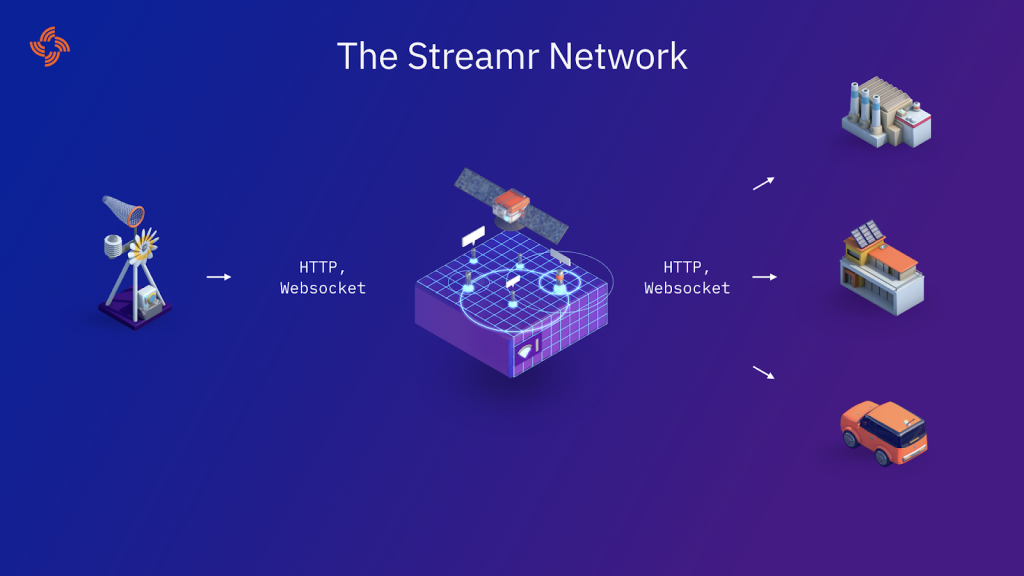
Building the missing protocol of today’s internet stack: a decentralized pub/sub network for realtime data
What is the Streamr Network? The Streamr Network is a scalable realtime messaging system, which enables applications and devices such as IoT sensors, connected cars, and basically all “smart”… Read more
See more Streamr guides